Running a Multi Node Hadoop Cluster on a Mac with Docker to Test the HDFS’s Fault Tolerance
The purpose of this article is to provide a simple, working, step-by-step tutorial on how to test for fault tolerance on a distributed system by setting up a multi node Hadoop cluster as an example and examining the contents of its HDFS, simulated through Docker on a Mac using a publicly available Docker repository, followed by a short evaluation of how this Hadoop’s HDFS Fault Tolerance mechanism performs under the CAP Theorem. Phew.
Let’s break that statement down, shall we?
First, read through all the topics under the Relevant Concepts section. Feel free to refer to the further reading links at the end of each section or hyperlinks if any terms or concepts are still unclear to you after my most-likely oversimplified explanations. On the other hand, feel free to skip all the way to the Tutorial section if you are already familiar with all the relevant concepts.
Relevant Concepts
Distributed Systems

A distributed system is a collection of multiple, independent components such as machines, servers, databases, or nodes. These components work together towards a common goal by splitting, “distributing” tasks and big data amongst themselves in a way that, in the end, a user interacting with it perceives it as one smoothly functioning interface. In a world of Big Data where one single computer simply can’t handle storing and processing a large continuous influx of terrabytes of data, distributed systems are one such solution. The biggest companies like Google and Amazon use them, and there are several softwares to choose and set them up with. However, they are often extremely tedious to set up and manage, so this article serves as an introductory tutorial to setting up and examining a simple example for yourself.
“Distributed systems are awful to write and suffer from a new class of bugs. If you don’t absolutely have to use a distributed system, then don’t!” ~a Distributed Systems Professor
Read more: My lesson plan for the first class I led in the Distributed Systems Tutorial I took (make sure to look at the provided readings and study guide)
Fault Tolerance

When a user accesses any system, say an ATM, or their phone, it can be off or on — either it “works” or it “doesn’t work”. However, depending on what you need from it, one part may not work and you may not even know it, but you still get what you need done. The ATM may not be able to withdraw at the moment, but you can still make a deposit. Your phone’s wifi might be broken, but you can still make an emergency call. Fault Tolerance is a distributed system’s ability to continue functioning despite a “partial failure” where one or more, but not all, of its exactly similar components fails. For a distributed database, this might mean that if one storage fails, then the specific files stored inside it aren’t gone forever and still accessible elsewhere. There are several mechanisms to implement it, several metrics to test it, and oh so many ways they can still fail you. Hey, distributed systems are hard to implement and manage remember?
Read more: Fault Tolerance Mechanisms in Distributed Systems
Apache Software Foundation

The Apache Software Foundation, Apache for short, is one of the world’s largest non-profit corporations founded in 1999. They provide various open-source software or “projects” designed for the public good — in fact, W3Techs reports that around 40% of all known websites use Apache software.
Hadoop

Apache Hadoop, commonly referred to as Hadoop, is one specific software developed under Apache that provides a framework for storing and processing large datasets. It is most appealing because it is open source and it‘s the biggest competitor to Google’s BigTable big data storage system.
The Hadoop framework is composed of four main “modules”:
- Hadoop Distributed File System (HDFS)
- Yet Another Resource Negotiator (YARN)
- MapReduce
- Hadoop Common
These modules serve as nodes and algorithms performed by these nodes that, when run together, form a cluster. This cluster is capable of performing tasks normally not possible on one computer because the input is too large or tasks are too computationally intensive, by working together — a fundamental principle for distributed systems.
It’s important to understand that Hadoop is actually a system of multiple distributed systems interacting with each other. MapReduce is an algorithm that performs distributed computing, the HDFS is a distributed storage system, YARN sets up the framework for what roles nodes need to play for the distributed system to exist and to run tasks, and there is a separate service called ZooKeeper that acts as its own cluster to provide distributed configuration service.
For this article, we will only be examining the HDFS as a distributed mechanism for data storage for simplicity.
Hadoop can be run as a software on its own, but it’s open-source nature means that it’s components or structure are also often used as a framework or for companies’ big data processing technologies (ex: Amazon’s Cloud).
At the time of writing, the latest version of Hadoop is 3.3.0, but the example I will be running in the example later is 3.2.1 as specified by the original Docker repository’s creator.
Fun fact: Hadoop’s name and logo design comes from the stuffed yellow elephant that the son of Hadoop’s creator, Doug Cutting, owned at the time.
HDFS
The HDFS is a distributed file storage system that provides a means for users to easily access data that is usually too big to store in one computer. Clients interact with it to store (write) files into it or access (read) already stored data. HDFS is a “write once read many” (WORM) type of data storage that ensures data cannot be edited once stored, only deleted. It follows what is conventionally known as a master-slave topology, but moving forward to a future where unnecessary references to slavery are no longer acceptable and normalized, I will refer to it as leader-follow topology instead.

In HDFS, there are two main components which clients interact with:
- a leader Active NameNode is responsible for splitting each input data into fixed max chunk sizes, replicating these chunks, and distributed each replica into different data nodes; it then stores information about which chunks each file is split into and where each chunk is located — we call this information metadata
- multiple DataNodes that simply store the chunk replicas; each DataNode can be an actual storage server, a physical computer, or a container
There’s also a backup Secondary or Passive NameNode that regularly syncs to the Active NameNode’s metadata, ready to take over should the Active NameNode fail. However, despite having important implications on the performance of the HDFS cluster as a whole, it is not the focus of today’s article as it requires more knowledge and technical experience to experiment with.
Overall, these simple components working together allow what normally wouldn’t be possible in one computer: storing and processing ever changing large amounts of data (in millions of numbers or in gigabytes of size), allowing highly scalable operations.
Fault Tolerance on HDFS

Fault tolerance is the ability of a system to continue functioning should one or more of its components experience an error. The HDFS is reported to be highly fault-tolerant in its data storage mechanism because of the replication mechanism described earlier. As of Hadoop 3, a new fault tolerance system was introduced called Erasure Coding that reduces the storage cost. But due to performance issues and simplicities sake, in this tutorial, I will be using Hadoop 3, but only use the standard replication mechanism and focus on exploring how the HDFS achieves fault tolerance through replication.
The replication mechanism (in detail):
- The HDFS splits an input file into blocks of the same max size (max size changes depending on the version: either 64MB or 128MB) that can later easily be put together when the file is retrieved
- It then creates a specified amount of copies of every block, an attribute called the replication factor and set to a default of 3, then distributes the replicas on multiple DataNodes.
- Thus, for a replication factor if one DataNode fails, there are at least two more DataNodes that store the same data.
- It is considered highly fault tolerant because the amount of replicas and the distribution of blocks in Hadoop is such that it is extremely unlikely (but still possible if you’re unlucky) that nodes containing one same block will fail at the same time and make it completely unrecoverable.
Hadoop Installation Modes
Hadoop can be installed in three different modes.
- standalone mode: a single node cluster of one active NameNode and one DataNode run on one computer that doesn’t require HDFS and stores files on the local host computer, while allowing you to use some limited Hadoop functionality
- pseudo distributed mode: a single node cluster of one active NameNode and one DataNode that now uses the HDFS in a means to simulate a multi node cluster on one machine; others on the internet say you could also have multiple DataNodes but still call it pseudo distributed mode
- distributed mode: a multi node cluster with one active NameNode and multiple DataNodes run on multiple containers, servers, or computers
For the experiment, we’ll be running Hadoop 3.2.1 in distributed mode through Docker containers.
Docker
Docker is a platform that allows users to implement containerization. A container is an environment where, unless otherwise specified, everything inside it like code or software are isolated from the hosting operating system. Containerization is the process of creating and sharing software or code through images to build these containers. An image is the sort of “blueprint” that docker uses to build the actual container and fill its contents. A repository is a collection of images. Our example will rely on a Docker repository graciously provided by programmers from Big Data Europe to set up a multi node Hadoop cluster components on different Docker containers for us. Note that every time a container is built, a corresponding volume is also built to store the container’s data, and these must be manually removed when a container is removed if you want a completely clean set-up.
Why do we need Docker for this?
Most distributed systems, in practice, use entire servers (that you’d have to pay for) or computers (physical, individual machines) for one node. If we were to actually run Hadoop in its full capacity, even just to test its HDFS capabilities, we’d have to buy servers or have to procure multiple computers. Most importantly, Hadoop is extremely tricky to set up without command-line expertise, knowledge of Hadoop and HDFS commands, and the skill to manage conflicting dependencies of which you are likely to run into when setting up your own Hadoop cluster. Because Hadoop was written in Java, it also requires you to install Java on Mac. However, finding the right version to smoothly create a Hadoop cluster that meets both my computer and any Hadoop version’s requirements, in my experience, has been almost impossible, let alone routing the correct versions to each other.
Docker allows us to run a fully distributed system, and in our case, Hadoop with multiple HDFS data nodes in different containers but on one computer. There is also a repository that does majority of the initial set-up for us so we don’t have to learn remotely as much of the things you’d have to learn if you set up Hadoop on its own.
Read more: The Docker-Hadoop repository from Big Data Europe
Tutorial
Specifications
I’m currently using a
- 2018 MacBook Air running
- macOS Catalina version 10.15.4.
I’ll be deploying a pre-made Docker repository running
- Hadoop 3.2.1 on my
- Bash Terminal through
- Docker 2.5.2
Before we do any testing, the tutorial below will let us set up a 5 DataNode Hadoop cluster, then store one file that will be replicated and randomly distributed. Ensuring a proper set up will help us get familiar with the Hadoop Framework, the HDFS, and make sure our experiments will run properly later.
Experiment Results
After running the hdfs fsck input/f1.txt -files -blocks -locations command, you should receive a similar output to the one below, but with different exact values. I’ve taken the liberty of spacing out and cutting down (with ellipses …) the output for readability.
Important Note: We’ll be running almost all commands from now on inside the NameNode container bash window. You’ll know you’re in it because your commands will always be prefixed by root@xxxxxxxxx:/#
root@010344ecfb0a:/# hdfs fsck input/f1.txt -files -blocks -locationsConnecting to namenode via http://namenode:9870/fsck?ugi=root&files=1&blocks=1&locations=1&path=%2Fuser%2Froot%2Finput%2Ff1.txtFSCK started by root (auth:SIMPLE) from /172.24.0.2 for path /user/root/input/f1.txt at Wed Dec 16 11:31:52 UTC 2020/user/root/input/f1.txt 12 bytes, replicated: replication=3, 1 block(s): OK0. BP-2050830227-172.24.0.2-1608549668355:blk_1073741830_1006 len=12 Live_repl=3 [DatanodeInfoWithStorage[172.24.0.6:9866,DS-3fbdbfef-a18f-48a0-bf63-b3258184262f,DISK],
DatanodeInfoWithStorage[172.24.0.3:9866,DS-a69f77b8-57ae-4406-a4a3-42912b37c3d2,DISK],
DatanodeInfoWithStorage[172.24.0.5:9866,DS-0438ce2b-2cdd-4be5-b1b7-7547b0fd3a25,DISK]]Status: HEALTHY
Number of data-nodes: 5
...
The output isn’t very neat and straightforward to understand even with the lines separated, so let me summarize. The first few lines are saying that file f1.txt was found and exists, and it was stored by the NameNode with the address 172.24.0.2 in the directory input/f1.txt. In the middle, it explains the metadata of file, saying it was stored as 1 block (understandably as the file is extremely small and the storage capacity of a DataNode is 64MB), and this one block was replicated 3 times, then stored in three different DataNodes.
Taking a closer look at these last few lines, we see exact addresses for the location of these replicas.
If you run hdfs dfsadmin -report you would receive information about all the DataNodes and their addresses.
root@c451677b4944:/# hdfs dfsadmin -report
...
-------------------------------------------------
Live datanodes (5):Name: 172.24.0.3:9866 (datanode2.docker-hadoop_default)
...
Name: 172.24.0.4:9866 (datanode4.docker-hadoop_default)
...
Name: 172.24.0.5:9866 (datanode1.docker-hadoop_default)
...
Name: 172.24.0.6:9866 (datanode5.docker-hadoop_default)
...
Name: 172.24.0.7:9866 (datanode3.docker-hadoop_default)
...
Based on the output for f1.txt, we can confirm that f1.txt was stored as 1 block and replicated then distributed to datanode5, datanode2, and datanode1. It’s also evident that there was some random mechanism to the assignment of which datanodes would receive the replicas.
To confirm one last time that the data was stored properly, we can even retrieve the file and ask the terminal to display the file’s contents with the command hdfs dfs -cat input/f1.txt.
root@010344ecfb0a:/# hdfs dfs -cat input/f1.txt2020-12-16 11:38:04,702 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = falseHello World
We got “Hello World” back just as we expected.
Primer: How HDFS achieves Fault Tolerance with its DataNodes
DataNodes in an HDFS all send “heartbeat” messages to the NameNode every 3 seconds to inform the cluster leader whether they are still alive/functioning or not. If a NameNode still doesn’t receive a heartbeat message from a DataNode after 10 minutes, it then considers that DataNode dead. This is important because the documentation is not clear on what information the NameNode returns within the 10 minutes that it does not declare a DataNode dead. This would be interesting to experimentally confirm and relevant to understanding the HDFS.
Furthermore, to maintain Fault Tolerance and ensure the file’s blocks still contain the right number of replicas at all times, the NameNode supposedly ensures that another DataNode will keep the contents of the dead DataNode and updates its metadata accordingly. Apparently, in this data backup, the other DataNodes don’t actually need to read the contents of the dead DataNode (which wouldn’t makes sense if the dead DataNode was unaccessible in the first place) and can copy the replica from elsewhere. But does this all happen in practice?
Read more: How NameNode handles DataNode failure
Fault Tolerance Testing Experiment
Here are some questions to guide us on experimenting with the HDFS’s DataNodes:
- What would happen to the other DataNodes and stored file if one of the DataNodes containing one of the three replicas, for example, datanode5, stopped functioning?
- Does the cluster consider the DataNode as “dead” after 10 minutes as it’s supposed to?
- Can you retrieve the file before the 10 minutes that the last remaining replica is marked as “dead”?
- At any point, does the HDFS compensate for the missing DataNodes’ data by copying it to another DataNode?
- At any point, does the HDFS automatically create revive or create new DataNodes without specification?
Let us experimentally find the answers to all those questions together using primarily these three important hdfs commands below.
# Retrieve and output the file
hdfs dfs -cat input/f1.txt# Display metadata of the file, including
# the amount of blocks the file is split into
# and each block's replica locations
hdfs fsck input/f1.txt -files -blocks -locations# See the status of the DataNodes in our cluster
# whether they're live or dead and their address
hdfs dfsadmin -report
Side Note: Managing and viewing your cluster on your browser

A quick note, the nginx container we ran earlier allows us to actually manage and view details about our cluster on our localhost or 0.0.0.0. If the 9870 link doesn’t work for you, run docker ps on a new Terminal window, then look under the “port” value of your namenode. For me, it was 0.0.0.0:9870->9870/tcp.
Read more: Networking features in Docker Desktop for Mac
As we’ve established, every DataNode sends a heartbeat message every 3 seconds. We’d know a DataNode was out of commission if, at anytime you refresh the page above and the “Last contact” is more than 3 seconds, that DataNode is down. For coherence, I will be prioritizing use the command line for this entire tutorial.
Results of Deleting 1 Replica Before 10 Minutes Has Passed
- What would happen to the other DataNodes and stored file if one of the DataNodes containing one of the three replicas, for example, datanode5, stopped functioning?
We’ve been running code in the bash terminal inside the namenode container. For now, open a separate Bash Terminal window, then go into the datanode and kill the datanode daemon running from within to simulate it “failing”.
docker exec -it datanode5 bashInside the datanode’s bash terminal, run the jps command to find the id of the DataNode to kill.
root@bd3bb8c1bad2:/# jps
1046 Jps
359 DataNodeRun the kill -9 [DataNode id] command such that
root@bd3bb8c1bad2:/# kill -9 359then after a few seconds, you should be kicked out of that container because the node no longer exists.
To make extra sure we’ve deleted the DataNode and all its corresponding contents, execute the both commands below.
docker rm -f datanode5
docker volume rm docker-hadoop_hadoop_datanode5
When you run docker ps, both the DataNode container and volume should no longer exist.
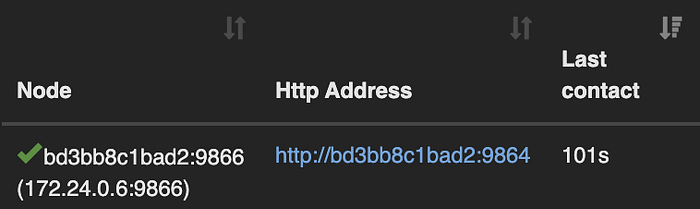
To further ensure that the DataNode no longer exists, you can even check the localhost:9870 window and see that the last contact with it (identify it based on its address) is more than 3 seconds.
Back to the namenode bash window, when we run the hdfs dfsadmin -report command before 10 minutes has passed since the deletion, interestingly enough, nothing about the DataNode’s information changes apart from the value in parenthesis (datanode5.docker-hadoop_default) changing to (172.24.0.6). Note, the decommission status remains the same because there is a way to safely decommission a DataNode, however, it is complicated to implement and does not simulate an unexpected real life fault or malfunction of a node in a distributed system.
root@010344ecfb0a:/# hdfs dfsadmin -report
...
Live datanodes (5):
...
Name: 172.24.0.6:9866 (172.24.0.6)
Hostname: bd3bb8c1bad2
Decommission Status : Normal
...Before the 10 minute window, can we still retrieve the file?
root@010344ecfb0a:/# hdfs dfs -cat input/f1.txt2020-12-16 12:00:00,267 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = falseHello World
Yes, because the command returned the “Hello World” text that we defined f1.txt to contain. Interestingly too, the file metadata also remains the same, but that may be because the NameNode has yet to update its metadata because it still doesn’t consider the DataNode dead.
root@010344ecfb0a:/# hdfs fsck input/f1.txt -files -blocks -locations
...0. BP-2050830227-172.24.0.2-1608549668355:blk_1073741830_1006 len=12 Live_repl=3[DatanodeInfoWithStorage[172.24.0.7:9866,DS-6c07f7bb-4c60-4632-a80d-edc1a7fa7a8f,DISK],
DatanodeInfoWithStorage[172.24.0.3:9866,DS-a69f77b8-57ae-4406-a4a3-42912b37c3d2,DISK],
DatanodeInfoWithStorage[172.24.0.5:9866,DS-0438ce2b-2cdd-4be5-b1b7-7547b0fd3a25,DISK]]Status: HEALTHY
Number of data-nodes: 5
...
Now, let’s wait until 10 minutes after the deletion has passed.
Results of Deleting 1 Replica After 10 Minutes Has Passed
- Does the cluster consider the DataNode as “dead” after 10 minutes as it’s supposed to?
Sure enough, after 10 minutes, running hdfs dfsadmin -report reveals to us that the datanode is indeed dead, returning the information from when it last sent a heartbeat message, but putting it under a new section called “Dead datanodes”.
root@010344ecfb0a:/# hdfs dfsadmin -report
Live datanodes (4):
...
Dead datanodes (1):
Name: 172.24.0.6:9866 (172.24.0.6)
...
Num of Blocks: 0Can we still retrieve the file?
root@010344ecfb0a:/# hdfs dfs -cat input/f1.txt2020-12-16 12:23:33,070 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = falseHello World
Yes we can, because we know there are other replicas.
Now, what does the HDFS tell us when we find the block replica locations? Is the missing replica copied over to another existing DataNode?
root@010344ecfb0a:/# hdfs fsck input/f1.txt -files -blocks -locations
...0. BP-2050830227-172.24.0.2-1608549668355:blk_1073741830_1006 len=12 Live_repl=3[DatanodeInfoWithStorage[172.24.0.3:9866,DS-a69f77b8-57ae-4406-a4a3-42912b37c3d2,DISK],
DatanodeInfoWithStorage[172.24.0.5:9866,DS-0438ce2b-2cdd-4be5-b1b7-7547b0fd3a25,DISK],
[DatanodeInfoWithStorage[172.24.0.7:9866,DS-6c07f7bb-4c60-4632-a80d-edc1a7fa7a8f,DISK]]Status: HEALTHY
Number of data-nodes: 5
...
It’s not immediately obvious, but the HDFS has successfully backed up the replica that was in datanode5 (172.24.0.6) to datanode3 (172.24.0.7). Fault Tolerance, although slower than I expected, is indeed implemented in HDFS.
Results of Deleting All 3 Replicas Before 10 Minutes Has Passed
- Can you retrieve the file before the 10 minutes that the last remaining replica is marked as “dead”?
Let’s delete all the DataNodes containing f1.txt’s replicas using similar commands above.
Before the 10 minutes are up, can the HDFS still retrieve the file?
root@010344ecfb0a:/# hdfs dfs -cat input/f1.txt2020-12-21 12:32:53,537 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = falseHello Worldroot@010344ecfb0a:/#
Strangely enough, it still can. Perhaps this is a cache issue I am unaware of. I thought that because the original DataNodes themselves were removed, even if there were replicas being made in the other live DataNodes, it would take some time for the replication to happen and the metadata to update, so we’d be unable to access the file in the meantime.
Let’s look at the DataNodes’ status. As you can see, the HDFS reports that there are still 4 live DataNodes — it seems the NameNode really only updates its metadata after it officially declares DataNodes dead.
root@010344ecfb0a:/# hdfs dfsadmin -report
Live datanodes (4):
...
Dead datanodes (1):
...As expected, the file block and replica information remain the same.
root@010344ecfb0a:/# hdfs fsck input/f1.txt -files -blocks -locations
...0. BP-2050830227-172.24.0.2-1608549668355:blk_1073741830_1006 len=12 Live_repl=3[DatanodeInfoWithStorage[172.24.0.3:9866,DS-a69f77b8-57ae-4406-a4a3-42912b37c3d2,DISK],
DatanodeInfoWithStorage[172.24.0.5:9866,DS-0438ce2b-2cdd-4be5-b1b7-7547b0fd3a25,DISK],
[DatanodeInfoWithStorage[172.24.0.7:9866,DS-6c07f7bb-4c60-4632-a80d-edc1a7fa7a8f,DISK]]Status: HEALTHY
Number of data-nodes: 5
...
Results of Deleting All 3 Replicas Before 10 Minutes Has Passed
10 minutes has passed and all the DataNodes with the replicas for f1.txt have been deleted. What happens when we try to retrieve the file? Immediately after deleting, I got an error message. That’s interesting, considering that back ups should have been made, even if only two datanodes are left, and thus, only two replicas are backed up.
root@010344ecfb0a:/# hdfs dfs -cat input/f1.txt-cat: Null exception message
...
What is the status of our DataNodes?
root@010344ecfb0a:/# hdfs dfsadmin -report
Live datanodes (2):
...
Dead datanodes (3):If we check the block and replica information of f1.txt after some time, this is where it gets interesting.
- Does the HDFS always successfully compensate for the missing DataNodes’ data by backing it up to another DataNode?
root@010344ecfb0a:/# hdfs fsck input/f1.txt -files -blocks -locationsConnecting to namenode via http://namenode:9870/fsck?ugi=root&files=1&blocks=1&locations=1&path=%2Fuser%2Froot%2Finput%2Ff1.txtFSCK started by root (auth:SIMPLE) from /172.24.0.2 for path /user/root/input/f1.txt at Wed Dec 16 12:49:57 UTC 2020/user/root/input/f1.txt 12 bytes, replicated: replication=3, 1 block(s): Under replicated BP-2050830227-172.24.0.2-1608549668355:blk_1073741830_1006. Target Replicas is 3 but found 2 live replica(s), 0 decommissioned replica(s), 0 decommissioning replica(s).0. BP-2050830227-172.24.0.2-1608549668355:blk_1073741830_1006 len=12 Live_repl=2
[DatanodeInfoWithStorage[172.24.0.7:9866,DS-6c07f7bb-4c60-4632-a80d-edc1a7fa7a8f,DISK],
DatanodeInfoWithStorage[172.24.0.4:9866,DS-90717ec2-4434-4bff-af1a-162208bc3fb1,DISK]]
Yes it does, although it turns out, I had to wait a few minutes even after the 10 minutes of initial DataNode deletion for the file’s block replica information to update!
Now that all the DataNodes containing f1.txt’s replicas were deleted, retrieving the file’s block replica locations reveals that there are two live replicas in the remaining datanodes.
Side note: There are two replicas only because there are only two remaining DataNodes. I separately reran the code to build 10 DataNodes and surely enough, when the 3 DataNodes containing the file replicas were deleted, 3 more replicas were made in the other live DataNodes. This phenomenon of there being less replicas than the replication factor does happen in real life, and it is called under-replication. HDFS will not put the same blocks in one node to prevent storage waste and will under-replicate in cases where there are less live nodes (with enough space) than the replication factor.
And when we try to retrieve the file, once again we are successful, although note that it also took a few minutes for the cluster to update the information, as I encountered a retrieval error at first.
root@010344ecfb0a:/# hdfs dfs -cat input/f1.txt2020-12-16 13:02:40,682 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = falseHello World
- At any point, does the HDFS automatically create revive or create new DataNodes without specification?
Nope! What’s gone is gone, and even after an hour of waiting, the deleted DataNodes remain dead to the HDFS. Consistent with the documentation, a fixed number of DataNodes are created when the cluster is deployed. Unless the entire cluster is otherwise backed up (not part of this tutorial), once a DataNodes is deleted or down rather than decommissioned, the cluster does not rebuild those DataNodes.
Evaluation under the CAP Theorem
CAP Theorem
Let’s do a quick review.
C — Consistency
A — Availability
P — Partition Tolerance
The theorem states that any Distributed System can only have two of the three characteristics. Consistency means that someone accessing a system will be shown the same data regardless of which node they access information from. This means that these nodes need to have the same data at all times whenever something new is written, otherwise, in the case of an error in writing, they should rollback to the latest available state or return an error. Availability means that any and all nodes will return a response when requested to change or reveal information. Partition occurs when there is a disruption in connection or communication between any nodes. Tolerance is the ability to continue overall function despite that partition. In reality, most distributed systems have varying levels of each property, such as having eventual consistency vs strong consistency. Furthermore, they won’t exclusively have none of the third property. They will just have lower levels of it, or some will have configuration settings that can be changed depending on the user’s need in time to make it more consistent, more available, or more partition tolerant, at the expense of another property.
Read more: IBM CAP Theorem Primer; Great YouTube Video Explaining the 2/3 Tradeoff; Illustrated Proof
HDFS CAP
Note that for this analysis, I’ll only be focusing on the performance of HDFS under the CAP Theorem regarding its DataNodes simply when storing or editing files and assuming that the NameNode does not fail.
Let’s analyze the results of our experiments, then confirm that with what the official HDFS documentation says.
From our experiments, the HDFS is indeed Partition Tolerant. In the case where one DataNode is down, the other DataNodes don’t cease to function. The NameNode, in fact, is able to to recognize which DataNodes are down, and, when requested to output a stored file, gain that same information within the dead DataNode from elsewhere. The NameNode can even back up that data on another live DataNode.
But between Availability and Consistency, the HDFS seems to more consistent in the fact that it always returns accurate information, whether that be the output of the stored file, or returning an error if it is not able to retrieve it. Remember when we tried to retrieve the file right after we deleted all the DataNodes containing all the original replicas? It returned a retrieval error — it indirectly acknowledges that it once had the file because it didn’t say that “the file does not exist” as it would have before the file was ever uploaded. A few minutes after the 10 minutes of deletion, we were once again able to retrieve the file, and found replicas in the other live DataNodes. This does, however, mean that it sacrifices its capability to immediately return a response from its nodes — the HDFS thus sacrifices Availability to be Consistent.
This is further corroborated by the official documentation. From Hadoop Version 2.7.2 onwards, once a file has been created, or deleted in the HDFS, “in-cluster operations querying the file metadata and contents MUST immediately see the file and its data.”
Furthermore, the official documentation also says that “the time to complete an operation is undefined and may depend on the implementation and on the state of the system.” We even got to observe this experimentally — although the NameNode would classify a DataNode dead around after 10 minutes since its last heartbeat message, it would take an unspecified amount of time past 10 minutes to back up the file replicas elsewhere, although it did eventually. This should further highlight how the system sacrifices Availability in this case.
As to whether the HDFS supports Eventually Consistent Reads or Strongly Consistent Reads, we first got an error, which is perhaps an accurate depiction of the NameNode experiencing read errors because of the outdated replica locations for the file at the time. I suspect that was due to the 10 minute delay and errors related to its metadata updating. This was then followed by the actual output of the file a few minutes later, which is still an accurate depiction of system-wide state of the file then. This supports the idea of the HDFS being Eventually Consistent. I later found that the official documentation also states that the HDFS storage is, in fact, Consistent, and specifically, “generally Eventually Consistent”. Note how the official documentation also specifically lacks an “Availability” section.
Read more: Official Documentation on Hadoop
Real life Impacts
With strictly this understanding of HDFS, this means that the system isn’t very reliable in the 10 minutes that a DataNode goes down. The performance of the system would also depend on the implementation, potentially requiring more time and expertise in the initial setup to minimize delays due to hardware, software, or cluster inefficiencies. Furthermore, in the event that three nodes go down simultaneously without giving the other DataNodes the opportunity to replicate the files in them, a complete data loss could occur. However, I didn’t test for that and that also seems extremely unlikely, as even a small time difference between the DataNode failures would allow for other DataNodes to replicate the data — again, that speed would depend on the implementation.
However, these tradeoffs does not negate the importance of the HDFS and its Fault Tolerance. With a cluster of many nodes, for storage of extremely important or sensitive information, being able to ensure that your file will not be edited or permanently unaccessible is something users can rely on the HDFS for. Furthermore, HDFS isn’t the only main HDFS-like Big Data Storage Systems. There are others that build on the open-source HDFS and compensate for this lost availability due to DataNode failure through creative ways more tailored to specific user needs. I empower you to continue your exploration into Distributed Storage Systems and slowly discover them.
Hope you enjoy going through this article as much as I did, and that you find it useful in your exploration into Distributed Systems.
